


As the researchers point out, “the overall inference steps required to solve the problem remain the same,” so this kind of difference is important when comparing results within different GSM symbolic runs and with GSM8K. Both cases are more than a little surprising. The fact that such small changes lead to such variable results suggests to the researchers that these models are not making “formal” inferences, but rather “attempts.” I’m doing it.[ing] It performs a type of within-distribution pattern matching, matching the given question and solution steps to similar ones found in the training data. ”
don’t get distracted
Still, the overall variance exhibited by GSM symbolic tests was often relatively small overall. For example, OpenAI’s ChatGPT-4o dropped from 95.2 percent accuracy on GSM8K to a still impressive 94.9 percent on GSM-Symbolic. This is a fairly high success rate using either benchmark, regardless of whether or not the model itself uses “formal” reasoning behind the scenes (although it is important to note that if the researcher takes one logical step to the problem) After adding just one or two, the total accuracy of many models dropped sharply).

An example of how some models can be misinterpreted by extraneous information added to the GSM8K benchmark suite.
An example of how some models can be misinterpreted by extraneous information added to the GSM8K benchmark suite.
Credit: Apple Research
However, because Apple researchers modified the GSM-Symbolic benchmark by adding “a seemingly related but ultimately unimportant statement” to the question, the LLM results tested were even more It got worse. In this “GSM-NoOp” benchmark set (short for “No Operations”), the question about how many kiwis you picked over multiple days was changed to include the additional detail “5 of them.” There is a possibility that [the kiwis] It was a little smaller than average. ”
Adding these dangerous issues results in what the researchers called a “catastrophic performance drop” in accuracy compared to GSM8K, ranging from 17.5 percent to a whopping 65.7 percent depending on the model tested. did. Such a significant drop in accuracy highlights the inherent limitations of using simple “pattern matching” to “translate sentences into operations without truly understanding their meaning,” the study says. they wrote.
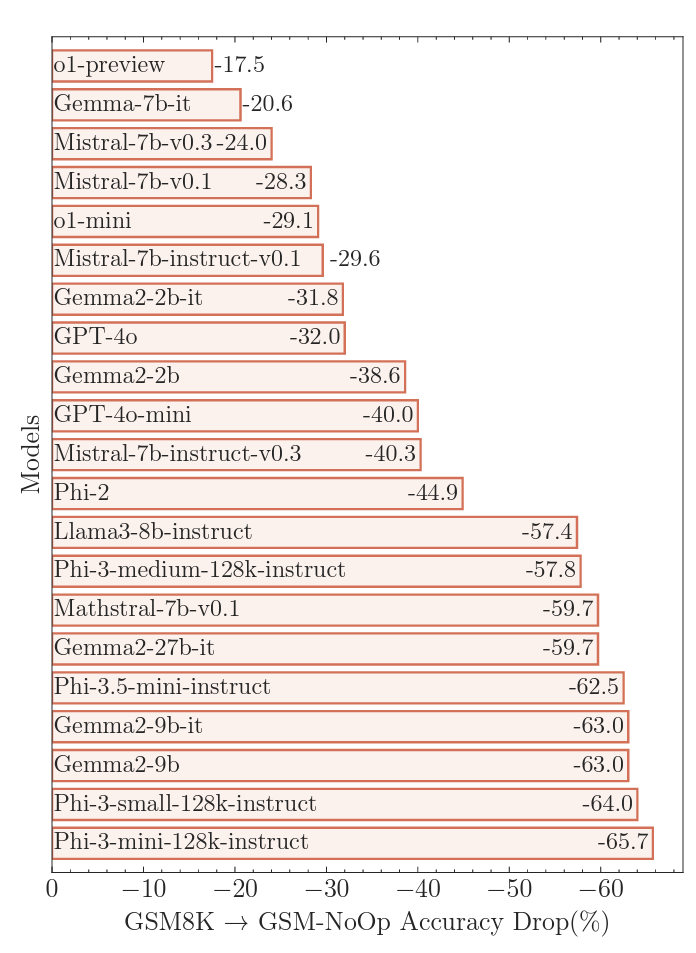
Introducing extraneous information into the prompts often causes “catastrophic” failures in most “reasoning” LLMs.
Introducing extraneous information into the prompts often causes “catastrophic” failures in most “reasoning” LLMs.
Credit: Apple Research
For example, in the smaller kiwi example, most models will try to subtract the smaller fruit from the final sum. The researchers speculate that the reason for this is that “the training dataset contained similar examples that required conversion to subtraction operations.” This is a type of “serious flaw” that researchers say “points to a deeper problem.” [the models’] “The inference process” cannot be helped by fine-tuning or other refinements.